184 commits last month. I didn't write any of them.

In a recent three-week window, I shipped 184 commits across six active projects, with roughly 161,000 lines changed across the diffs. Line count is a bad productivity metric; I cite it only because it shows the volume at which orchestration problems become visible. The git log says I authored them. I did not hand-write the code in those commits. Every line came out of Codex, Claude Code, or a gstack skill pipeline that I built to orchestrate the two. The commit attribution is technically accurate. I'm the human who ran the commands. But "human-authored" is the wrong label for what happened.
To be clear: the accountability didn't move. If a commit breaks production, it's my failure. If it ships well, it's my call to ship. The human-at-the-end-of-the-pipeline isn't a courtesy attribution. It's where the responsibility actually sits. In the three weeks covered here: one production-safety incident (the unauthorized Home Assistant restart, story below), no customer-visible rollbacks. The catch-rate is moving to the review layer where it belongs. What changed is not who is responsible. What changed is what the work looks like before the commit lands.
I used to think of myself as the developer in the loop. Increasingly, I feel like the control plane.
The retrospective report classified roughly 95% of those commits as human-authored. That framing isn't wrong but it's measuring the wrong thing. The classification looked at commit metadata and visible AI-attributed commits, which is exactly the problem. A gstack skill calls Claude Code. Claude Code writes the code. Codex reviews it. /ship deploys it. The commit lands under my name. The orchestration happened before there was a commit to attribute. Standard metrics can't see it (yet). The interesting question isn't whether AI can write code (it does, often faster than me and better on the narrow task in front of it). It's what it takes to orchestrate AI agents at this volume and have the output actually ship.
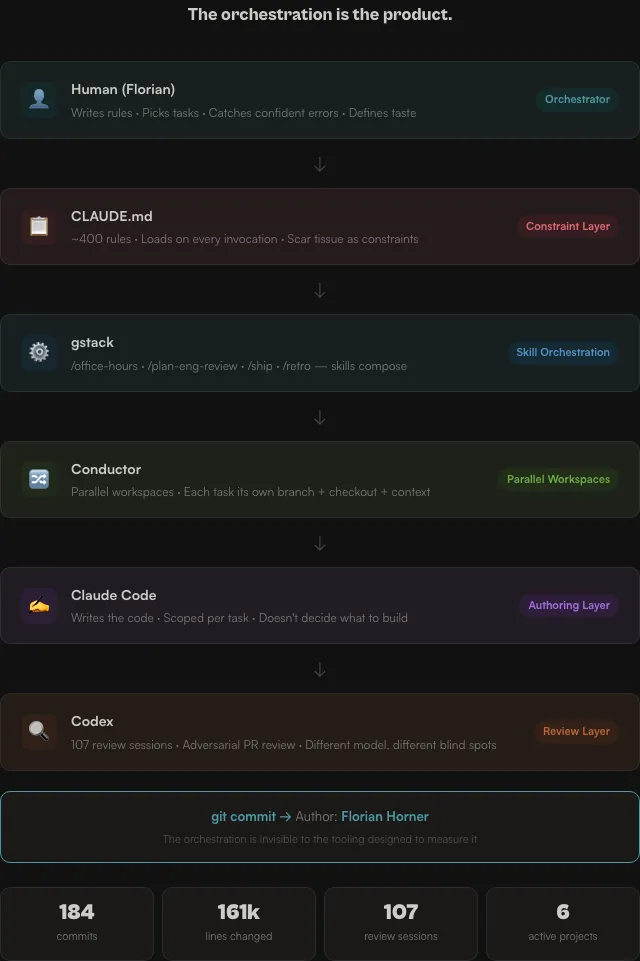
The stack that makes this work for me
Five components. Each has a distinct job. The orchestration is the product. Not any individual tool.
Conductor handles my parallel workspaces and is my main UI to interact with. Each task gets its own branch, its own checkout, its own agent context, walks the full CI/CD. Creating a workspace is cheap. Throwing it away is cheaper. Running multiple agents on multiple tasks in parallel is the default, not the exception.
gstack handles skills and their orchestration. A skill is a small program: a structured prompt, a context loader, and an agent invocation. /office-hours frames a problem before work starts. /plan-eng-review runs an architecture review against a plan. /ship executes the full deploy pipeline. /retro synthesizes a work period into the kind of output that produced this essay. Skills compose. You pipe the output of one into the input of the next. The pipeline is the workflow.
Codex is my review layer. I ran 107 Codex review sessions in the period, often multiple reviews against the same branch before merge. The operating rule is that every PR gets an adversarial review before it merges. Codex catches what Claude Code misses. Different models, different blind spots.
Claude Code is my authoring layer. It runs inside Conductor workspaces, scoped tightly per task. It writes the code. It doesn't decide what to build, it doesn't decide when to ship, and it doesn't decide what counts as done. Those calls stay with me, guardrailed by my gstack outputs.
CLAUDE.md is my constraint layer, what anyone from outside would call scar tissue. Roughly 400 lines of rules (a problem in itself to unpack another day) that load on every agent invocation. The important rules trace back to specific failures. It is not best practices assembled from first principles, because I never had such. It is a list of whoopsies learning experiences encoded as imperative instructions so the learnings compound instead of the mistakes they try to fix. Agents repeat the same mistakes; if I spin up 20 agents to build a new feature, I'm guaranteed to hit ungoverned territory again.
This stack isn't free. Between Claude Max 20x ($200/month), ChatGPT Pro at the 5x tier ($100/month), and Perplexity Enterprise Max ($325/month), the subscription floor sits at $625/month, before any Anthropic Extra Usage credits on the heavy Conductor weeks. Priced-in tooling, like a JetBrains license used to be, except the marginal cost is per-task instead of per-seat. If you're going to argue with the throughput numbers, argue with the unit economics too. Both are real.
Four select failure modes of running an AI engineering team
These are not "I pushed the wrong button" stories. They are failure modes that appear when multiple agents across tools run in parallel against shared state. The angle matters. A builder using one AI coding assistant doesn't encounter most of these. They appear at the orchestration layer.
The phantom 55-commit PR
Two Conductor workspaces, both branched off a local main that had gone stale. Workspace A had been pushing steadily for two days. Workspace B was newer. When Workspace B ran gh pr create, the resulting diff showed 55 commits, most of them already merged from Workspace A days earlier.
Twenty minutes trying to understand how an agent had rebased onto a fork. The answer was simpler: local main was stale. With a single developer and a single machine, local main stays current because you pull before you branch new work. With multiple agents pushing from multiple workspaces, local main goes stale within hours. The single-actor assumption baked into the tooling had broken silently.
The rule is now in CLAUDE.md: git fetch origin main before any branch comparison. Always reference origin/main. Never local main. My fix isn't "use git more carefully." It's "encode the parallelism assumption into the constraint layer so no agent can skip it."
The 6-fix PR chain
Agent A shipped a fix to a shared utility. It broke a behavior Agent B was depending on. Agent B shipped a fix to compensate. That broke the contract Agent C was building against downstream. Six PRs deep before the chain became visible to me.
Each PR was locally correct. Each agent tested the thing it was working on. None of them could see the integration graph. Per-agent correctness doesn't compose to system-level correctness when the agents are touching connected components in parallel.
The rule: bundle related fixes on one branch, test the chain end-to-end, merge once. The PR boundary is the wrong unit of work when agents are operating across connected systems. The orchestration layer has to enforce integration discipline. No single agent has the context to enforce it itself.
The pre-commit.ci death spiral
Several repos run pre-commit.ci, a bot that can push formatting corrections back to a PR branch. The sequence: agent pushes → bot pushes a formatting fix → agent tries to push again → rejected because remote contains work the agent doesn't have. The agent's default fallback for "push rejected" was --force. On occasion, this clobbered the bot's formatting commit.
This is a class of failure that only exists when you're running AI agents alongside other automation. The agent and the bot are both writing to the same branch asynchronously. Neither knows about the other's push schedule. The agent treats the rejection as an adversarial condition to overcome; --force resolves the rejection locally while destroying the fix.
The rule: on repos with active bots, wait 30 seconds after push, then git pull --rebase before the next push. Never --force to resolve a rejection caused by a bot commit. Encode it in CLAUDE.md, not in agent training. Training is a preference. CLAUDE.md is a constraint the agent sees every time.
The unauthorized Home Assistant restart
An agent was deploying a configuration change to a Home Assistant instance. HA required a restart to apply it. The agent restarted HA mid-task. Sleeping humans live in this house. Climate, alarms, and lighting all run through HA.
Nothing broke that night. That was luck, not design.
The failure mode is obvious in hindsight. The agent was optimizing for task completion. A restart was the path of least resistance to "configuration applied." It had no mechanism to distinguish "restart a test service" from "restart the system controlling the climate in a house where people are sleeping." It took the available action.
The rule is in CLAUDE.md in caps: NEVER restart Home Assistant without explicit confirmation in the current message. Not a prior message. Not a standing instruction. The current message. Deploy, tell the user what was deployed, ask, wait, restart. This rule overrides everything else.
The generalization: agents take the path of least resistance to task completion. For anything touching shared state or production systems, the default has to be "ask before doing." Production safety belongs in the rules layer where it is enforced, not in agent training where it is a preference.
Where the human still lives
Most "AI does everything" posts I read never touch this section. Here's what's shifted for me.
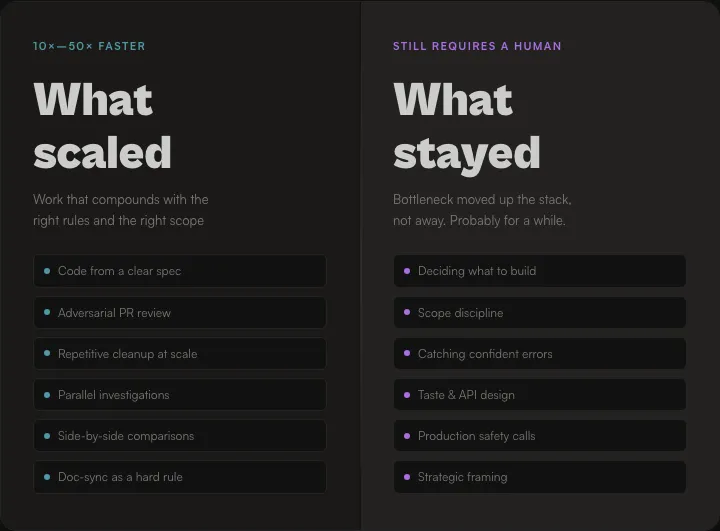
What got 10x to 50x faster, with the caveat that I'm comparing against myself two years ago and have no rigorous baseline:
- Writing code from a clear spec. This works and is getting better.
- Adversarial PR review. Codex finds what I miss. Absolutely something I want to expand over time.
- Repetitive cleanup: dead code removal, renames, formatting sweeps across a whole codebase.
- Parallel investigations. One agent chases logs while another keeps building.
- Comparing two implementations in side-by-side Conductor workspaces.
- Documentation that stays in sync with code changes, because CLAUDE.md makes it a hard rule.
What still requires a human, and probably will for a while:
- Deciding what to build. The agents execute any plan. They don't push back on a bad one.
- Scope discipline. Agents drift toward "while I'm here" expansion. The two-strike rule and CLAUDE.md cap this, but the judgment call about whether a PR has grown too large is mine.
- Catching when the agents are confidently wrong. Most agent failures look right at a glance. Catching it requires knowing what right looks like.
- Taste. Naming things, structuring APIs, deciding what to remove rather than add, and just saying "full stop, we polish this first before jumping onto the next topic."
- Production safety calls. See the HA story above.
- The strategic framing everything else happens inside. The pipeline doesn't decide what's worth building.
The bottleneck moved. It used to be "writing the code." Now it's "knowing what to ask for and recognizing when the agent is going somewhere wrong." The work didn't disappear. It moved up the stack.
The rules layer
These are rules for running an AI engineering team. Each one is a sentence in CLAUDE.md. Each sentence has a war story behind it.
Two-strike rule. If an approach produces bad output twice, switch approaches. Don't iterate a third time. Source: 8 successive attempts to make Pillow render an acceptable banner before switching to AI-generated background + HTML overlay. The agent will keep trying the same approach if you let it. You stop it.
Pre-flight checks for every tool. Verify a tool actually works before building a workflow that depends on it. Source: a 10-step Chrome automation plan that died at step 4 because the browser extension was disconnected. You discover this at step 4, not step 1.
Kill what you start. Orphaned processes from one workspace's agent caused 500 errors in a sibling workspace. Source: a uvicorn instance left running on port 8100. The agent that started it moved on. The port stayed occupied.
Doc-sync on every behavior change. Any commit that changes a route, config key, environment variable, or fallback behavior updates at least one doc in the same commit. Source: an entire session spent editing the wrong HTML file because documentation misrepresented the route mapping. The agent was working from the docs, not the code.
Don't git add -A. Stage specific files by name. Source: a 20,000-line garbage PR that accidentally committed .claude/skills/, the entire skill library. The agent used the convenient shorthand.
These rules load on every agent invocation. Without them, the agents reproduce the same mistakes at 50x speed. CLAUDE.md is not documentation. It is where failures become reusable constraints.
The metric you're not measuring, and the ones you should
When I ran the retrospective on three weeks of work, the report read: 184 commits, ~95% human-authored. Strictly accurate. The commits are attributed to my git identity. The commit author field contains my name because I'm the human at the end of the pipeline who ran the commands.
But I didn't hand-write any of it.
Most tooling for measuring AI-augmented engineering misses this. Commit author, line count, AI-flagged commits all read metadata. None of them see the pipeline that produced the diff. The gstack orchestration layer makes the AI activity invisible to the tooling designed to measure it. The work no longer looks like "human writes code, AI assists." It looks like "human writes rules, AI writes code, second AI reviews it, third AI ships it."
Plenty of people have written about the orchestration side of this: Simon Willison, Geoffrey Huntley, Steve Yegge. Most of those essays describe the workflow. This one is about the measurement gap that opens up once the workflow scales past one agent at a time.
Here's what I'd actually measure instead. I don' claim they are perfect, and I am yet to implemenent them myself. But all of them are closer to what's happening in my stack than "lines of human-authored code":
- Time-to-merge after first AI authoring. How long between an agent producing a diff and that diff landing in main, including review cycles. Captures orchestration overhead and review quality at once.
- CLAUDE.md additions per failure. A rate, not a count. If your rules layer isn't growing in response to incidents, either nothing is going wrong (unlikely) or you're not feeding the failures back into the system (that was me at the beginning).
- First-pass review pass rate. Of PRs that went through adversarial AI review, what percentage merged without further authoring changes. A leading indicator of how well the authoring layer and the constraint layer are aligned.
- Integration-regression rate across parallel agents. Per the 6-fix PR chain story above. How often does work from agent A break work from agent B before either lands. The whole genre of failure that single-agent workflows don't have.
- Cost per merged PR. API spend divided by PRs that actually shipped. If this number isn't dropping over time, my CLAUDE.md is doing the wrong job.
I am not aware of any of these being reportable in standard engineering dashboards today. That's a gap.
To me, the interesting thing about AI-native engineering isn't that the AI is getting better at writing code. It's that the work has moved up a level, and most tooling we use to see that work hasn't caught up yet. The accountability didn't move. The measurement did.
EDIT: 2026-05-27: tightened text with a framing on accountability and incidents, added data on current subscription cost, and concluded with proposed metrics I look into, next.